Contexte
Pour exploiter et maintenir le homelab de manière professionnelle, j’ai déployé une stack de supervision complète en LXC Debian 12 sur Proxmox. L’objectif : visibilité totale sur les équipements réseau, les hyperviseurs et les applications, avec centralisation des logs — comparable à un environnement de production.
Architecture de supervision
Équipements réseau (SNMP) ──→ Zabbix 7.0.26 (LXC 105) ──→ Dashboards / alertes
MariaDB (LXC 104) ──────────→ Backend DB Zabbix
Hyperviseurs PVE-01/02 ──────→ node_exporter :9100 ──→ Prometheus 3.5.3 (LXC 106)
└───→ pve_exporter :9221 ──→ ↓
Endpoints HTTP/TCP/ICMP ─────→ blackbox_exporter :9115 ─→ Grafana 13.0.1 (LXC 108)
Logs journald PVE-01/02 ─────→ Grafana Alloy 1.16.1 ──→ Loki 3.6.7 (LXC 107) ──→ Grafana
LXC dédiés (VLAN 10 MGMT)
| LXC | CTID | VLAN | Service | Version |
|---|---|---|---|---|
lxc-mariadb-01 | 104 | VLAN 10 MGMT | Base de données Zabbix | MariaDB |
lxc-zabbix-01 | 105 | VLAN 10 MGMT | Zabbix Server + Frontend | 7.0.26 |
lxc-prometheus-01 | 106 | VLAN 10 MGMT | Prometheus | 3.5.3 LTS |
lxc-loki-01 | 107 | VLAN 10 MGMT | Loki | 3.6.7 |
lxc-grafana-01 | 108 | VLAN 10 MGMT | Grafana | 13.0.1 |
Ce que j’ai fait
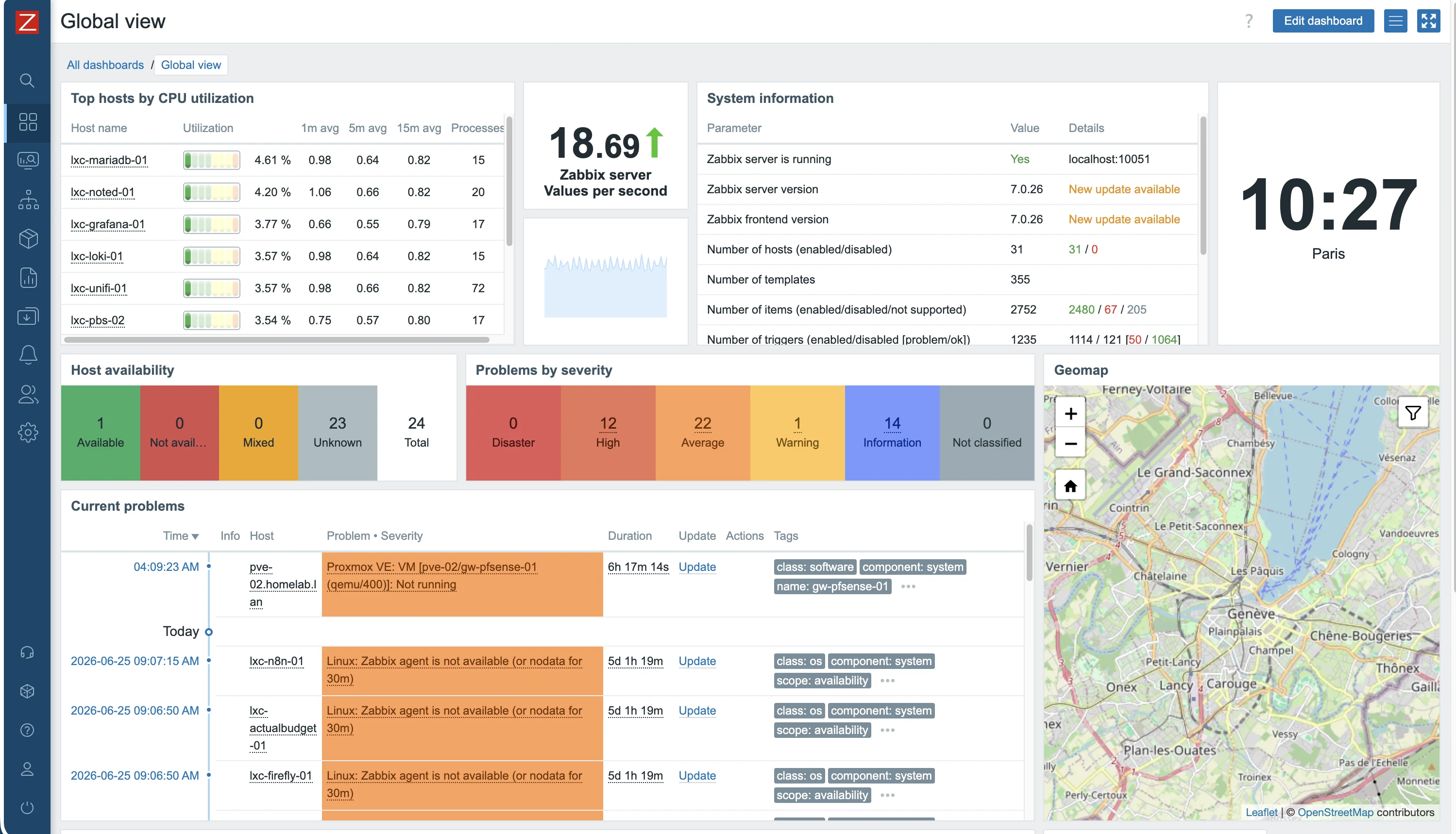
Zabbix 7.0.26 — supervision réseau SNMP
- Déploiement Zabbix Server + frontend Apache + MariaDB en LXC séparés (découplage)
- Correction d’un piège : l’utilisateur MariaDB
zabbixétait déclaré sur l’IP du LXC Zabbix (pas en wildcard%), ce qui nécessitaitskip-name-resolvecôté MariaDB pour éviter les reverse-DNS lookups - Upgrade vers la 7.0.26 : réinstallation du dépôt apt officiel, import du schéma SQL complet
- Configuration SNMP sur Cisco 3560-CX, D-Link DGS-1210-08P et pfSense (community string restrictive)
- Ajout des templates automatiques Zabbix par équipement
- Tuning des triggers pour supprimer les faux positifs (interfaces LLD, seuils verbeux)
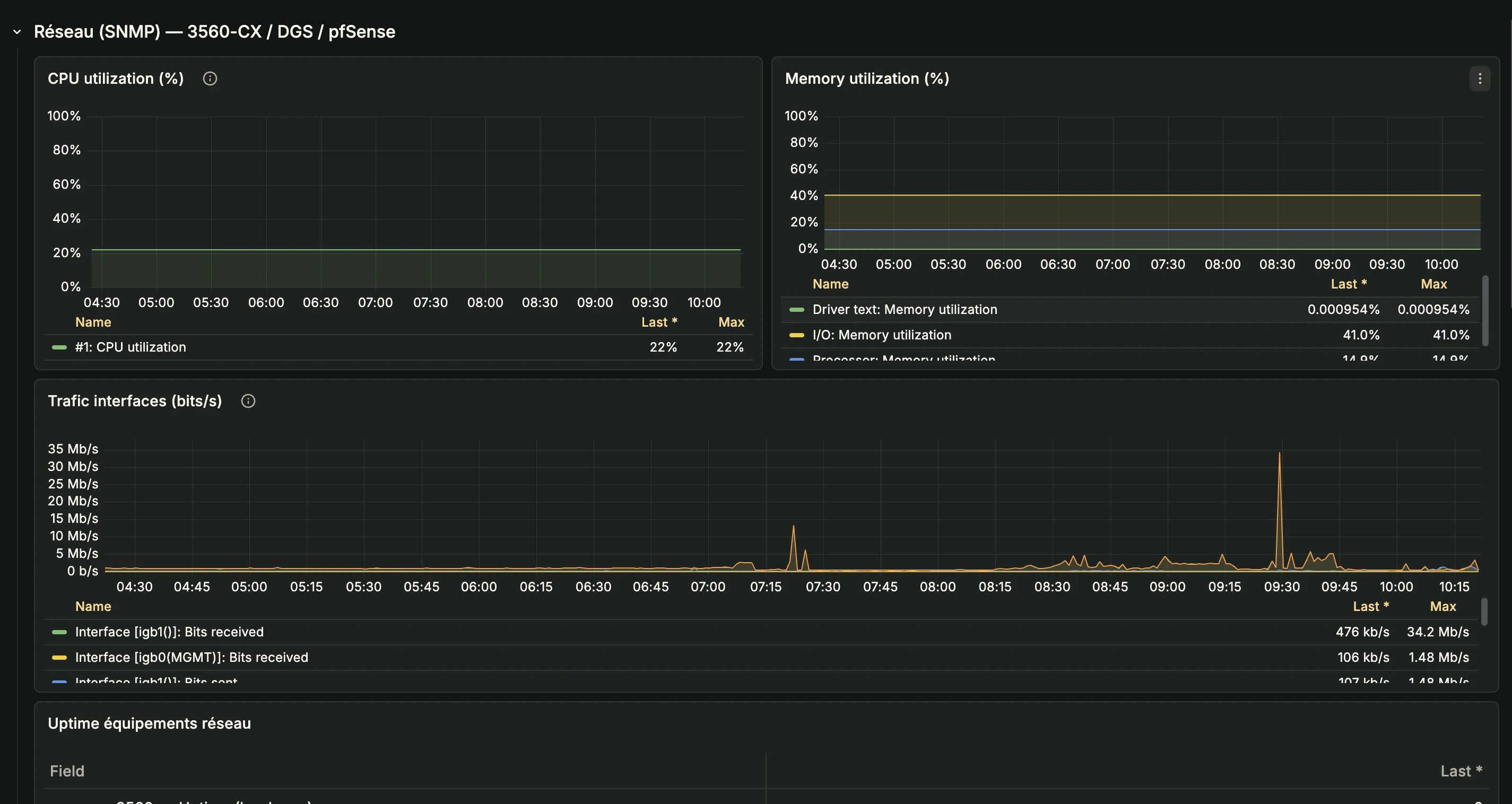
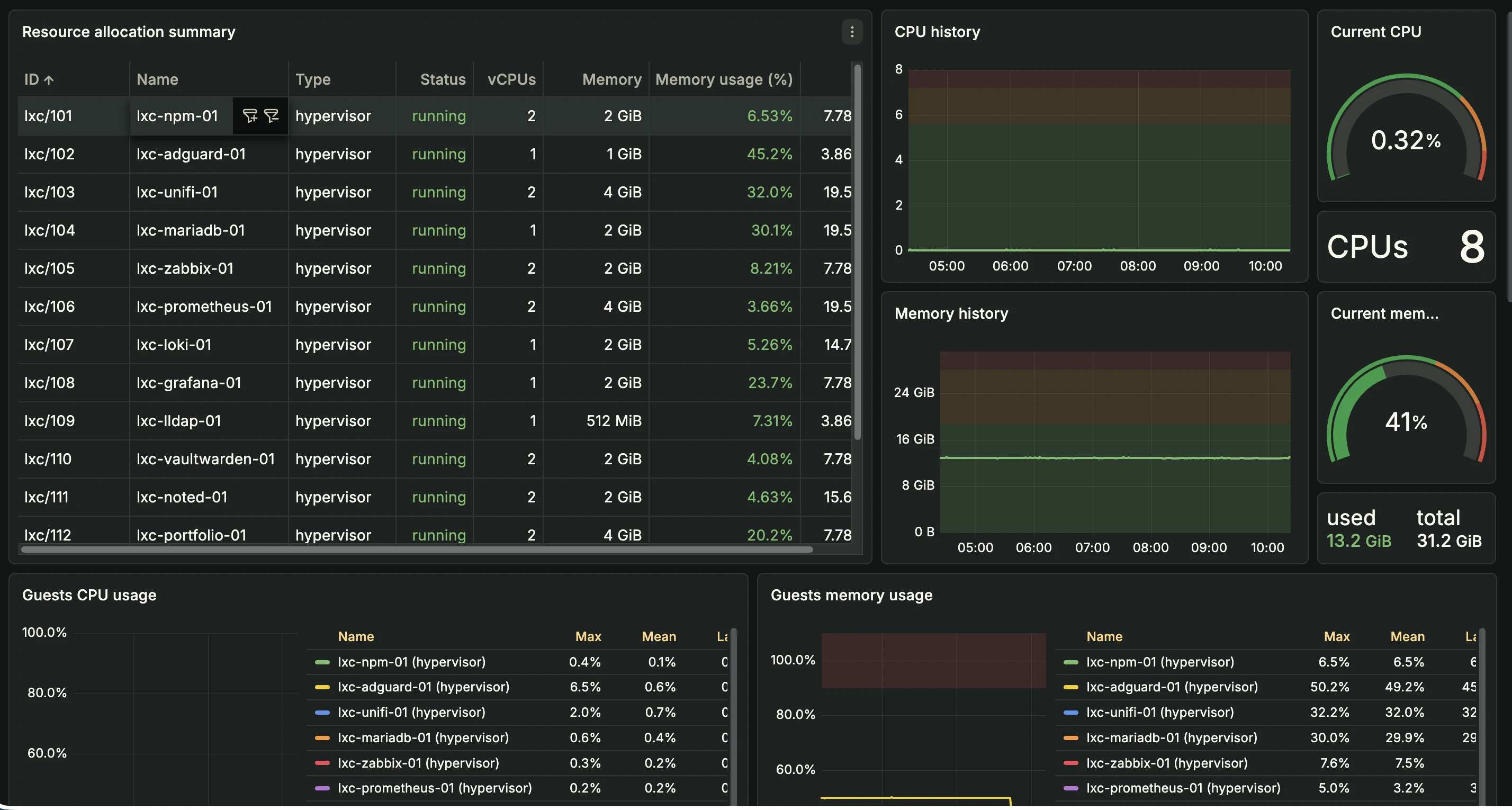
Prometheus 3.5.3 — métriques hyperviseurs et services
- Déploiement avec unit systemd et activation de l’API lifecycle (
--web.enable-lifecycle) - Configuration de 12 job_names dans
prometheus.ymlpour 37 targets au total :node: PVE-01 + PVE-02 vianode_exporter(port 9100)pve: PVE-01 + PVE-02 viapve_exporter(port 9221, relabeling target)blackbox_icmp: 6 targets (gateways + 1.1.1.1)blackbox_tcp: 5 servicesblackbox_https: 15 endpoints NPM + Cloudflareblackbox_dns_*: 6 jobs DNS (AdGuard, Unbound, Cloudflare)
- Correction d’un piège sur le lifecycle : le flag
--web.enable-lifecyclemanquait dans l’unit systemd, rendantsystemctl reloadsans effet
Grafana 13.0.1 — visualisation unifiée
- Datasources : Prometheus et Loki configurés
- Dashboards importés et personnalisés : Proxmox (via pve_exporter), réseau, disponibilité endpoints
- Requêtes LogQL dans Grafana pour filtrer les logs Proxmox par service systemd (
unit)
Loki 3.6.7 + Grafana Alloy 1.16.1 — centralisation des logs
- Loki déployé en mode monolithique single-binary (schéma v13/TSDB/filesystem, rétention 30j)
- Abandon de Promtail (EOL mars 2026) au profit de Grafana Alloy (successeur officiel, basé OpenTelemetry)
- Purge de masse des Promtail résiduels sur 10 LXC + 1 VM + 2 hôtes via
pct exec - Déploiement de Grafana Alloy v1.16.1 sur PVE-01 et PVE-02 : collecte du journal systemd complet (Proxmox, kernel, tâches VM/CT)
- Validation bout-en-bout : labels
host=pve-01/host=pve-02présents dans Loki, requêtes LogQL opérationnelles
Compétences mobilisées
Ce projet couvre l’exploitation et la supervision d’infrastructure (B2.4), la gestion du patrimoine informatique via l’inventaire automatisé Zabbix (B1.1), la garantie de disponibilité et d’intégrité via les logs centralisés (B3.4) et la détection d’anomalies réseau via les blackbox probes Prometheus (B3.5).